This post highlights some of the pitfalls you can run into while crawling for domains, whether you’re using PBN Lab’s expired domain crawler, or any other domain crawler out there. Domain crawling is easy…right? “Isn’t there a magic list of sites out there I can crawl, that will just land me hundreds of amazing expired domains?” Sadly, no. Thankfully nobody has actually asked me that question at all, but I’m sure everyone is hoping that’s the case. If there is a magic list, I’d love to know about it! Using the keyword search built in to PBN Lab, you’ll find that crawling seems almost too easy to start with. You simply throw in keyword or two, and wollah! You’ve got a hundred expired domains in your list, and you excitedly analyze each and every one of them. And more than likely amongst the list there are 1 or 2 keepers. But unfortunately the initial buzz of easily finding your very own expired domains can quickly wear off – if you don’t continue to see great results from your crawls. And where I see most people go wrong is that they’re not crawling in a systematic fashion, and it can easily lead you down the path of constantly crawling the same sites, or the same network of sites. This results in finding “more of the same” types of domains, with very similar metrics. Or worse still, you’ll keep getting duplicate domains. FYI: PBN Lab’s expired domain crawler will determine that you’ve already discovered an expired domain, and will flag it as a duplicate. This means you can quickly avoid wasting time and energy, simply by filtering duplicate domains...
One of the greatest challenges in crawling for expired domain names, is knowing where to crawl. You don’t need to know how to crawl, because this is taken care of by the expired domain crawler you’re using with PBN Lab, and while there are some variations we can implement, the process itself doesn’t vary greatly. In this post I’m sharing with you the systematic approach I use to constantly reveal great expired domains. This is almost literally a formula for finding domains. And the best part is…you don’t need to think hard, you just need to fill in the blanks! Why just 10 domains? Couldn’t I find more? You’ll find thousands of domains. But the real question is, how many of those are worth keeping? Each crawl reveals around 70 domains on average. Generally 3 to 5 of those are “good” domains, and 1 in 10 crawls will return a great domain. You could use this method to find hundreds of expired domains, you just need to repeat this process over and over. Aiming for 10 domains is realistic, you might find lots more. It depends on a lot on what you’re expecting in terms of metrics and other factors. But by putting this systematic approach into action, it’s simply just a matter of putting the expired domain crawler to work, and let it do all the heavy lifting. The real challenge is working out which domains to keep, and which to ignore! A systematic approach to domain crawling This is essentially a game, where you provide 5 easy answers to some relatively simple questions. For this to work for you, all you’ll need is a little knowledge of your niche (one would...
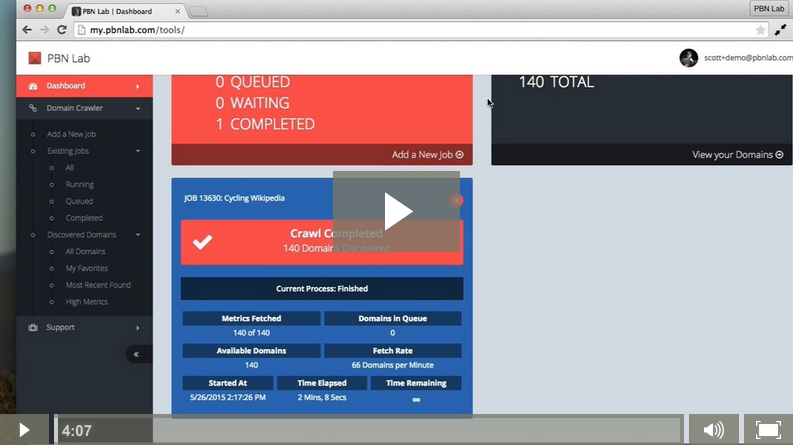
It goes without saying that Wikipedia is one of the most trusted resources online. It’s the 7th most popular web site in the world according to Alexa, and a domain authority of 100 – it’s clearly not getting any better than that. Most, if not all, Wikipedia articles must cite their sources, and link out to those sources. These sites, not unlike other sites on the net, will quite often be left to rot and die. Whatever the topic, you’ll be able to find expired domains specific to your niche – and they’ll come preloaded with backlinks from Wikipedia. While the links are “nofollow”, they are great links to have all the same – as each document in Wikipedia has been authored (or had its changes approved) by a real human being, who has been given special privilege to be an editor of the site. As a result, Wikipedia links are considered “trustworthy” in the eyes of Google. Using PBN Lab, you can quickly crawl those pages and find the expired domain names. In this video, I demonstrate how to perform a quick Google search, grab the source code directly from the search engine results page (SERP) and have the job wizard automatically load the Wikipedia pages as the seed URLs for your crawl. Then I take a quick look at the results which reveal a few strong expired domains, with links directly from Wikipedia, or from other authority sites whose page links to the expired...
Interested to see how this works, or what it really looks like? The following video is the “welcome” training video to new users, and shows just how easy it is to crawl for expired domains. In this off-the-cuff recording, I spent just 20 seconds starting a new crawl, which returned 61 expired domains. Many were good, and at least 3 were quality domains, with great Trust Flow and Majestic Flow ,with Trust Flow Topics closely related to the niche I was searching for. Video transcript: Welcome to PBN Lab! In this video I’m going to give you a quick crash course on how to crawl for expired domains. We’ll start by setting up a new job, then we’ll have a quick look at the results page. Once you log in after activating your account, you’ll be presented with the dashboard. I think you’ll agree with me that dashboard is very bare, and somewhat minimalistic. That’ll change soon enough and the big space down the bottom here is where the live job stats will appear. In the red panel you can see an overview of your crawl jobs, whether they’re running, queued, waiting or completed. And in the black panel is a quick overview of the domains you’ve found. Let’s get started by clicking Add New Job. The first step in the process is giving the new job a name. It can be anything you like, and ideally should reflect what you’re about to search for – because you’ll see this job name in the results page. In step 2, we’ll be adding a list of seed URLs, which is a...
I’m excited to announce in the latest crawler engine, I’m now fetching the much loved TrustFlow and CitationFlow metrics (among others) from Majestic SEO. And as you’d expect, you can filter your results view on-the-fly to display only domains with great TF and CF – to eliminate all the rubbish domains in just a few clicks. One big step closer to public...



Recent Comments