
 This post highlights some of the pitfalls you can run into while crawling for domains, whether you’re using PBN Lab’s expired domain crawler, or any other domain crawler out there.
This post highlights some of the pitfalls you can run into while crawling for domains, whether you’re using PBN Lab’s expired domain crawler, or any other domain crawler out there.
Domain crawling is easy…right?
“Isn’t there a magic list of sites out there I can crawl, that will just land me hundreds of amazing expired domains?” Sadly, no. Thankfully nobody has actually asked me that question at all, but I’m sure everyone is hoping that’s the case. If there is a magic list, I’d love to know about it!
Using the keyword search built in to PBN Lab, you’ll find that crawling seems almost too easy to start with.

You simply throw in keyword or two, and wollah! You’ve got a hundred expired domains in your list, and you excitedly analyze each and every one of them. And more than likely amongst the list there are 1 or 2 keepers.
But unfortunately the initial buzz of easily finding your very own expired domains can quickly wear off – if you don’t continue to see great results from your crawls.
And where I see most people go wrong is that they’re not crawling in a systematic fashion, and it can easily lead you down the path of constantly crawling the same sites, or the same network of sites.
This results in finding “more of the same” types of domains, with very similar metrics. Or worse still, you’ll keep getting duplicate domains.
FYI: PBN Lab’s expired domain crawler will determine that you’ve already discovered an expired domain, and will flag it as a duplicate. This means you can quickly avoid wasting time and energy, simply by filtering duplicate domains out of your results view.
You might well find yourself throwing your hands in the air in frustration, and I wouldn’t hold it against you.
But don’t despair, because there is a simple, systematic approach to crawling for expired domains you can take when setting up your crawl jobs and avoid the frustration.
In PBN Lab, your duplicate domains are highlighted, so you don’t waste time with them.
How not to crawl for expired domains:
Let’s establish what to avoid when crawling for expired domains.
1. Keyword burn-out:
Using PBN Lab’s expired domain crawler, you can simply enter keywords to find expired domains related to your niche. This works exceptionally well, and I do highly recommend crawling this way. It’s more time-efficient, and requires less mucking around.
But, if you’re targeting keywords or phrases, and you’re simply swapping out one or two keywords for other similar terms, you’re mostly just wasting your time and will burn out quickly.
I’m sure most people are aware that Google’s search is “semantic”, and it’s part of what makes Google’s SERPs so much more relevant than other search engines.
This means that even if you’ve used different synonyms as your keywords for your search, some of your searches are essentially the same as a previous search and in turn this means some of your crawls will be the same as a previous crawl.
To demonstrate, here are some examples of (very) poor keyword search terms:
- bicycle shoes
- bike shoes
- bicycle footwear
- cycling footwear
- shoes for cycling
Did you spot the issue? Bicycle, bike and cycling. Shoes and footwear. They’re different words, and they’re in a different order, but the search is for the same thing, you’re just phrasing it differently.
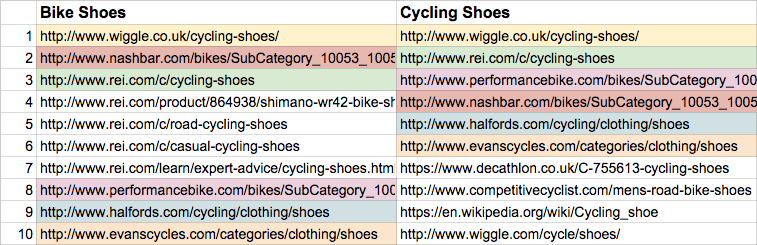
Comparing Bike Shoes and Cycling Shoes. You can see that the results are only 40% unique.
Google’s search engine is smarter than you and I, and sometimes it knows what you really mean, even if you don’t.
As you can imagine, based on the above searches, the results returned by the domain crawler would be very similar. Because in reality you’ve just performed 1 crawl, 5 times over.
2. Trying another Country:
Your next obvious step is to simply change the country, just to mix it up a bit.
When you specify a country in the keyword search, you’re asking Google to return you the results as though you’re a user from that region in the world. This does exactly as you’d expect, and Google will vary the their results, but they generally don’t vary by a lot.
To give you an extreme example, let’s say you searched for the keyword “online dictionary” using Australia as the country. The top result is dictionary.reference.com. Performing the same search using United States as the country, will also produce the top result of dictionary.reference.com.
We can see that Google believe dictionary.reference.com is “the best resource” online for both Australia and the United States of America.
While this may not seem like the greatest example – it demonstrates clearly that despite the fact Reference.com is a US-based service, it’s still the best resource in both cases, regardless of the region.
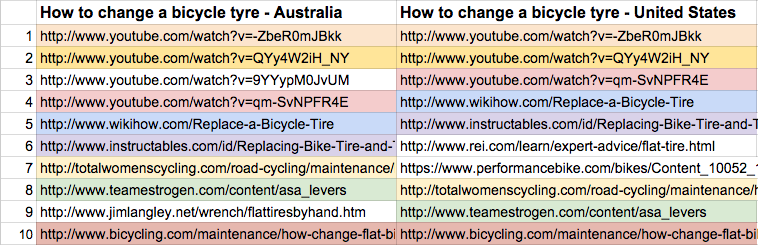
Comparing Google Australia’s results to United States. They’re only 20% different.
Of course this doesn’t just apply position 1 on the SERPs. You’ll find this pattern will continue right through the results.
Why? Well in short, if a site’s content is good, and the site is authoritative on the topic, and the content is not especially specific to any particular region of the world – there’s a great chance it’ll still be the best resource for Google to serve up to any/every region.
In short: by simply changing the country parameter only, it’s likely that you’ll end up creating a list of seed URLs where 80% of those seed URLs have already been crawled as part of a previous job.
4. Going back in time:
And when you change the year parameter, again this will only vary the seed URLs slightly. In my experience, to an even lesser extent than changing the country.
Check out my comparison below between Australia, United States in 2015 and United States from 2011. These three searches are just under 27% unique!
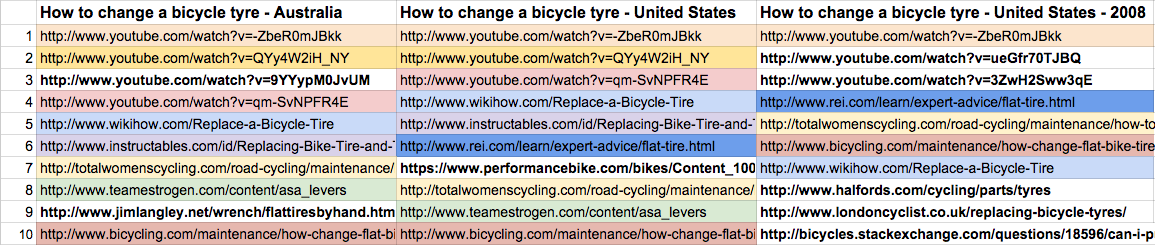
Google Australia 2015 vs United States 2015 vs United States 2011. Overall the results are only 27% unique!
The year parameter is useful however, when you really want to drill back in time to SERPs that were more relevant around a given event, where it’s likely those results were vastly different. For instance, if you were searching for sites around the London Olympics in 2012, the obvious year to specify would be 2012.
4. Endlessly crawling authority sites (like Wikipedia):
There’s a notion that to find a quality expired domain with great metrics, that you must crawl massive authority sites, or sites with high metrics themselves.
This is another easy trap you can fall into when crawling.
While it’s true that the link juice from these authority sites have helped increase the metrics of the domains you’ll find – it doesn’t mean that you shouldn’t look outside these sites. Because you know who else links to that site? Countless other sites.
Let’s take crawling Wikipedia for domains as an example.
You’d be mad not to crawl it. The site has amazing metrics, and we know each article has outbound links – sometimes hundreds of links from a single article. And chances are, amongst those links are dead links, and sometimes those the dead links are as a result of expired domains. Happy days!
Dead Links are often a result of an expired domain, but not all links are marked dead!
But crawling Wikipedia (or any other site for that matter) over-and-over, isn’t very productive. Not to mention the fact that “everyone is doing it” and chances are, someone else has likely snapped up a domain yesterday that you would’ve otherwise found today.
You don’t have to crawl authority sites to find domains that have great metrics.
Long story short: don’t expect to find endless nuggets of gold on a single site, no matter how big or authoritative the site is.
Recent Comments